
Fra NILUs årsrapport 2017: I løpet av det siste tiåret har behovet for informasjon og data eksplodert, og denne «datarevolusjonen» har også nådd forskningen. Innen miljøforskning spiller informasjon en stadig viktigere rolle – til det punkt at forskere nå til og med vet hvordan peisen din ser ut.
Fra NILUs årsrapport 2017: – Datainnsamling er det avgjørende steget innen de fleste miljøforskningsområder. Når vi utvikler høyoppløselige utslippsoversikter for både luftforurensning og klimagasser, er det viktigste å skaffe data av høy kvalitet, forklarer Susana Lopez-Aparicio, seniorforsker ved NILUs avdeling for by og industri.
Vedfyringsdata en utfordring
En av de største utfordringene er karakterisering av utslipp fra vedfyring til boligoppvarming. I Norge er vedfyring en viktig kilde til oppvarming i hjemmet, og dessuten sterkt forbundet med kos og hygge. Det er ca. 2,5 millioner ildsteder i landet, og over halvparten av dem antas å være i regelmessig bruk. Vedfyring i boliger gir ikke bare et varmt hjem, det er også en av de viktigste bidragsyterne til skadelige luftforurensende stoffer som partikler (PM) og polysykliske aromatiske hydrokarboner (PAH). Vedfyring er dessuten en viktig kilde til svart karbon, en kortlivet klimadriver.
Lopez-Aparicio forklarer videre: – Når vi skal karakterisere utslipp fra vedfyring til boligoppvarming, trenger vi informasjon om vedforbruk i husholdningen, type ildsted (f.eks. type peis, ny eller gammel ovn), tidsperioden vedfyringen skjer og type bolig. Sistnevnte indikerer høyden der utslippene kommer inn i atmosfæren. Når vi arbeider på byskala, trenger vi høyoppløselige data i både rom og tid, og denne informasjonen er sjelden enkelt tilgjengelig.
«Folkemengdekunnskap»
I iResponse-prosjektet (http://iresponse-rri.com), finansiert av Norges forskningsråd, har NILU-teamet utviklet og evaluert ulike metoder basert på crowdsourcing. Konseptet crowdsourcing er basert på å samle idéer, data og/eller tjenester fra en stor gruppe mennesker ved hjelp av informasjons- og kommunikasjonsteknologi (IKT). Det er definert som det nye paradigmet innen kunnskapsdannelse. Et av målene for iResponse er å ta for seg utfordringene og mulighetene knyttet til datainnsamlingsmetodene som brukes til å forbedre forståelsen av utslipp fra vedfyring for boligoppvarming.
– I iResponse brukte vi to forskjellige datainnsamlingsmetoder, forklarer Lopez-Aparicio, som også koordinerer prosjektet. – Den første metoden er basert på publikumsdeltakelse i form av spørreundersøkelser, den andre på automatisk datautvinning fra nettportaler.
Får folk til å delta
Lopez-Aparicio og teamet hennes designet og testet to metoder basert på publikumsdeltakelse. Begge tok sikte på å samle inn geolokaliserte data om vedforbruk per person, hva slags ildsted de brant veden i, og når de fyrte.
Den første metoden var basert på et eksisterende verktøy for å samle inn folks kunnskap om sitt nærmiljø basert på geografiske informasjonssystemer (Maptionnaire; https://maptionnaire.com). Case-studier ble gjennomført i Oslo, Akershus, Sarpsborg og Fredrikstad, noe som resulterte i rundt 1000 geolokaliserte svar med informasjon om folks vedfyring og miljøoppfatning.
For den andre metoden utviklet de et eget verktøy for å samle inn vedfyringsdata. Dette verktøyet gir deltakerne noe tilbake, i form av informasjon om de økonomiske kostnadene og miljøpåvirkningen forbundet med vedfyringen deres.
– Vi identifiserte viktige utfordringer innen datainnsamling basert på publikumsdeltakelse, så som frivillig engasjement, datakvalitet og representativitet i prøven, forklarer Lopez-Aparicio. – Det krever betydelige ressurser for å oppnå representativ deltakelse, og å skaffe data av god nok kvalitet til bruk i miljøforskning er ganske utfordrende.
Automatisk datautvinning
Når du utvikler en utslippsoversikt for boligoppvarming, handler noen av de viktigste spørsmålene om hvor ildstedene er, og i hvilken type bolig. Når forskerne vet dette, kan de identifisere vedfyringspotensialet for bestemte områder. Så iResponse-prosjektet utviklet en metode for automatisk datautvinning fra nettportaler som inneholder denne type opplysninger.
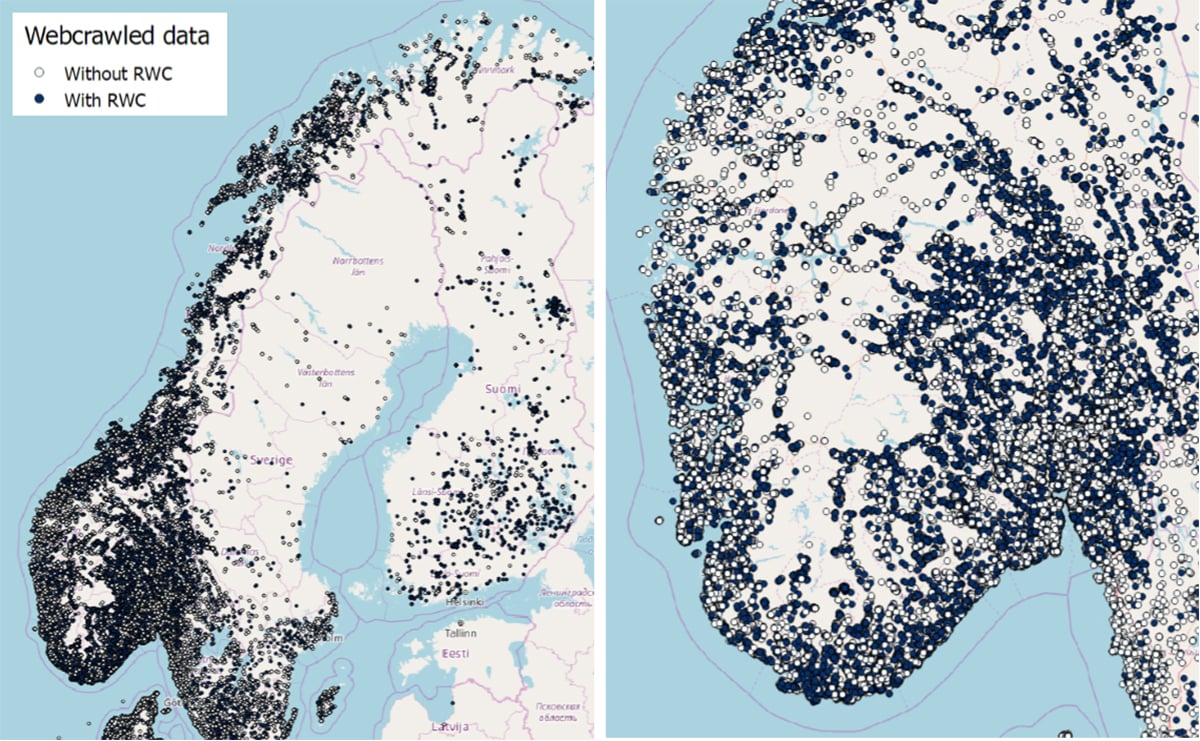
– Vi utviklet en såkalt «web crawling»-metode, sier Lopez-Aparicio. – Den henter ut den geografiske plasseringen av boliger annonsert på Finn.no, den norske rubrikkannonsenettsiden som inneholder brorparten av alle norske boligannonser. Annonsene inneholder både bilder og detaljerte beskrivelser av boligene, inkludert type oppvarming (f.eks. varmepumpe, fjernvarme, vedovn) og boligtype (f.eks. enebolig, leilighet, tomannsbolig).
Bruker maskinlæring til å klassifisere ildsteder
NILU-teamet utviklet videre en modell for bildegjenkjenning og klassifisering basert på maskinlæring. Basert på bildene hentet fra Finn.no, identifiserer modellen ildsteder og klassifiserer dem med henholdsvis 81%, 85% og 91% sikkerhet for åpne peiser, gamle ovner og nye ovner.
Dataene samlet inn via web crawling var avgjørende for utviklingen av en modell for å estimere høyoppløselige utslipp fra vedfyring. Dette arbeidet utføres i MetVed-prosjektet, finansiert av Miljødirektoratet og ledet av Lopez-Aparicio. Her har analysen av data fra forskjellige kilder vist hvor viktig datatilgjengelighet er, og dessuten understreket behovet for mer åpne data.
– Arbeidet vårt viser tydelig potensialet slike metoder har for å skaffe data med høyt detaljnivå, noe som er avgjørende for utviklingen av utslippsoversikter på urban skala, avslutter Lopez-Aparicio.
